煦霖智能即將亮相iote 2019蘇州物聯網展,展示高科技研發新成果

隨著物聯網技術的飛速發展,全球產業正迎來新一輪的智能化浪潮。在這一背景下,專注于高科技產品研發與生產的煦霖智能宣布,即將盛裝亮相iote 2019蘇州物聯網展。此次參展不僅是煦霖智能技術實力的一次集中展示,更是其深耕物聯網領域、推動行業創新的重要里程碑。
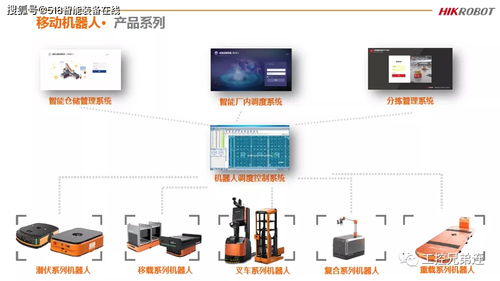
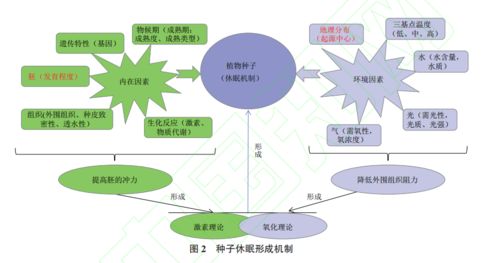
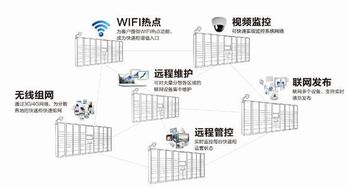
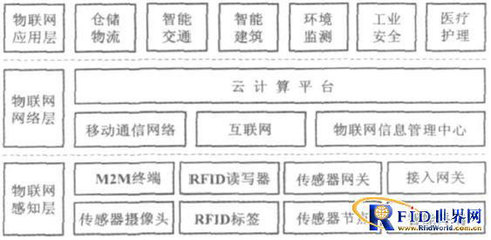
煦霖智能自成立以來,始終堅持以技術創新為核心驅動力,致力于物聯網相關技術的研發與應用。公司匯聚了一批在硬件設計、軟件開發、數據分析及系統集成方面經驗豐富的專業團隊,通過持續投入研發資源,已在智能傳感、邊緣計算、無線通信及云平臺構建等關鍵技術上取得了突破性進展。其產品線覆蓋智能家居、工業監控、智慧城市及健康醫療等多個領域,旨在通過穩定可靠的物聯網解決方案,賦能傳統行業轉型升級,提升社會運行效率與人們的生活品質。
iote 2019蘇州物聯網展作為中國乃至亞太地區頗具影響力的行業盛會,為物聯網產業鏈上下游企業提供了展示、交流與合作的絕佳平臺。煦霖智能此次參展,將攜其最新研發成果亮相,包括新一代低功耗廣域網(LPWAN)通信模塊、高精度環境監測傳感器、以及基于人工智能算法的智能分析平臺等核心產品與解決方案。參觀者不僅能夠在現場親身體驗這些高科技產品的卓越性能,更能深入了解煦霖智能如何將前沿的物聯網技術轉化為切實可行的行業應用,解決實際場景中的痛點與挑戰。
對于煦霖智能而言,參加iote 2019不僅是展示窗口,更是學習與汲取行業前沿動態的寶貴機會。通過與同行專家、合作伙伴及潛在客戶的深入交流,煦霖智能期待進一步洞悉市場趨勢,驗證技術方向,并探索更廣泛的合作可能。公司堅信,在萬物互聯的時代,唯有持續創新、開放協作,才能把握機遇,引領發展。
煦霖智能將繼續秉持“創新驅動,智聯萬物”的理念,加大在物聯網核心技術上的研發投入,不斷完善產品與服務體系。公司致力于成為值得信賴的物聯網解決方案提供商,通過科技的力量,為構建更加智能、高效、便捷的世界貢獻自己的力量。iote 2019蘇州物聯網展的亮相,正是煦霖智能邁向這一宏偉目標的關鍵一步,讓我們共同期待其在展會上的精彩表現。
如若轉載,請注明出處:http://m.nwknh.cn/product/16.html
更新時間:2026-06-18 07:43:02